Qwen3-Next 系列全解析:80B-A3B 的混合架构,Instruct 与 Thinking 双线能力进化
7 min read

Qwen 团队推出了新一代混合架构系列 —— Qwen3-Next,以 80B 总参数(80B-A3B)与稀疏激活(每次仅激活约 3B 参数)为核心设计思路,显著提升在长上下文、高并发与低延迟场景下的性价比。本系列包含两个主打方向:
Qwen3-Next-80B-A3B-Instruct:强调指令理解、对齐与稳定输出,不产生思考轨迹(无<think></think>)。Qwen3-Next-80B-A3B-Thinking:面向深度推理,默认包含思考轨迹(有<think></think>;模板可能只显示闭合标签),推理链长度较前代更长。
参考来源:
- Hugging Face(Instruct/Thinking 模型卡与集合)
- Qwen 官方博客与社区资料
- OpenRouter 模型页与第三方综述(ai-bot.cn 等)
为什么是 Next:三大工程目标
- 成本与吞吐:
80B 总参 × ~3B 激活,让推理像小模型一样高效,同时保持大模型能力上限。 - 长上下文与稳定性:针对 32K+ 长文本进行优化,兼顾关键要点召回与结构化输出稳定性。
- 生产可用性:强调延迟与并发表现,适配在线 API、企业知识问答与智能体工作流。
架构一览:Gated DeltaNet × Gated Attention × MoE
- Gated DeltaNet(速度优先)
- 设计为长文本处理优化,内存占用近似线性增长,流式生成更快,适合高并发服务。
- Gated Attention(精度优先)
- 在关键位置进行精确信息召回,确保长文本生成不丢失关键信息、段落结构更稳。
- 大规模 MoE 专家系统
- 社区资料显示包含多达 512 个专家;请求时仅动态路由少量专家(如 Top-K + 共享 1),实现负载均衡与计算节流。
- 原生 MTP(Multi-Token Prediction)训练
- 预训练阶段即引入多 token 预测,减少推理步数、提升长文吞吐,降低响应延迟。
Instruct vs Thinking:如何选型
-
Instruct(生产对话/Agent 首选)
- 不输出
<think></think>思考块,格式与对齐稳定,便于集成到产品化场景(如客服、表单生成、结构化 JSON/Markdown 输出)。 - 指令遵循与格式控制更强,易于模板化与评测。
- 不输出
-
Thinking(深度推理/复杂任务)
- 默认在提示模板中加入思考标记,用于生成/保留思考轨迹;在不同前端模板下可能只见到闭合
</think>标签属正常现象(由官方模板控制)。 - 链式推理能力更强,可在多步逻辑、数学/编程推导中获得更高准确率与稳定性。
- 默认在提示模板中加入思考标记,用于生成/保留思考轨迹;在不同前端模板下可能只见到闭合
实践建议:
- 面向“严格格式、快速上线”的业务选 Instruct;
- 面向“复杂推理、学术与工程推导”选 Thinking;
- 也可在 RAG/Agent 中按任务类型动态路由到不同版本。
能力与表现(社区汇总)
- Instruct:在多个指令与多任务基准上对齐或逼近更大规模(如 235B)的旗舰模型表现,尤其在长文本与吞吐上具优势。
- Thinking:在推理能力上优于同类轻量/快推理模型(有报告称在部分指标上超过 Gemini 2.5 Flash-Thinking),可输出更长的思考链。
注:具体分数以官方模型卡与第三方评测为准;本文聚焦能力侧画像与工程取舍,不复刻具体数值。
典型应用场景
- 长文摘要与报告生成:技术白皮书、法律协议、研究综述等的分段抽取与结构化成文。
- 代码生成与重构:跨文件理解、重构建议、测试样例生成与代码走查。
- 企业级知识问答(RAG):支持多语言问答、事实召回与可追溯引用。
- 智能体工作流:在工具调用、记忆管理与格式输出上表现稳健;可 Instruct/Thinking 混用。
- 高并发在线服务:低延迟响应与稳定对齐,适合商业化 API 服务。
快速使用(概览)
- Qwen Chat 网页版:可直接切换 Instruct/Thinking 体验(视官方提供)。
- 阿里云百炼(Model Studio):按官方文档调用生产 API,推荐用于企业场景。
- Hugging Face:按模型卡说明加载,会提供默认聊天模板;Thinking 版本会自动注入
<think>模板片段。 - OpenRouter:可用
qwen/qwen3-next-80b-a3b-instruct等模型名,走 OpenAI 兼容接口。
提示:Thinking 版本可能输出较长思考内容;如需隐藏,可在系统提示或后处理阶段剔除
<think>...</think>。
与上一代/同级别模型的对比要点
- 相对 Qwen3-32B 等密集模型:Next 通过稀疏激活获得“更低成本 × 更高吞吐”,长上下文下更具规模优势。
- 相对传统 MoE:在路由与门控上引入 Gated DeltaNet/Gated Attention 的混合设计,更好平衡速度与精度。
- 相对万亿级旗舰:社区称 Instruct 在部分指令基准已逼近 235B 旗舰表现,Thinking 在推理上大幅进步,但总体上 Next 着重“快与稳”的生产可用性。
相关链接
- Hugging Face(Thinking):https://huggingface.co/Qwen/Qwen3-Next-80B-A3B-Thinking
- Hugging Face(Instruct):https://huggingface.co/Qwen/Qwen3-Next-80B-A3B-Instruct
- Qwen 官方博客(Qwen3 系列):https://qwenlm.github.io/blog/qwen3/
- 第三方综述(中文):https://ai-bot.cn/qwen3-next/
- OpenRouter 模型页:https://openrouter.ai/qwen/qwen3-next-80b-a3b-instruct
更多文章
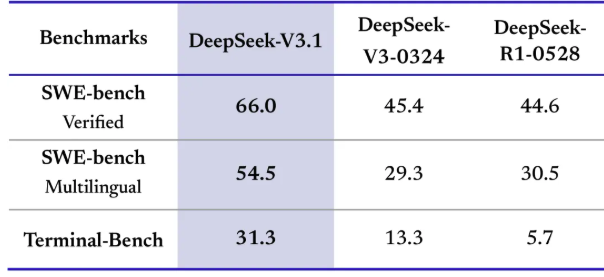
DeepSeek V3.1:混合推理、强劲编程与 Agent 能力,支持Claude Code,性价比再升级

Qwen-Image-Edit 图像编辑介绍与 ComfyUI 使用指南
沉浸式翻译插件重大安全漏洞:网页快照功能导致用户敏感信息大规模泄露
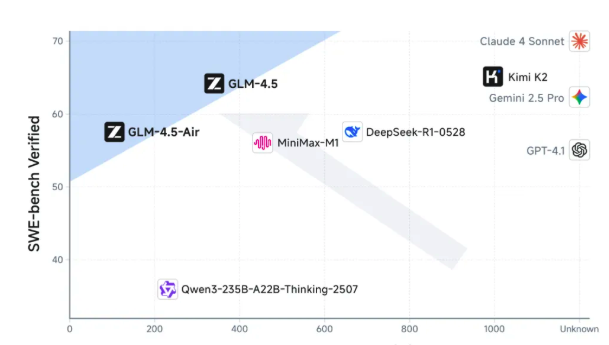
GLM-4.5技术报告与应用体验:国产智能体大模型新标杆
Win11Debloat 深度指南:一键精简 Windows 11,告别臃肿,提升系统性能
阿里Qwen-MT翻译模型重磅升级:92种语言、秒级响应,挑战GPT-4翻译霸主地位

Kimi K2如何凭借三大创新炼成万亿开源模型?
Docker运行macOS教程:Linux系统完整配置与部署指南

Qwen-TTS重磅发布:阿里云方言语音合成新巅峰,API极速体验!